
关系型数据库最难的地方,就是建模(model)。
错综复杂的数据,需要建立模型,才能储存在数据库。所谓”模型”就是两样东西:实体(entity)+ 关系(relationship)。
实体指的是那些实际的对象,带有自己的属性,可以理解成一组相关属性的容器。关系就是实体之间的联系,通常可以分成”一对一”、”一对多”和”多对多”等类型。
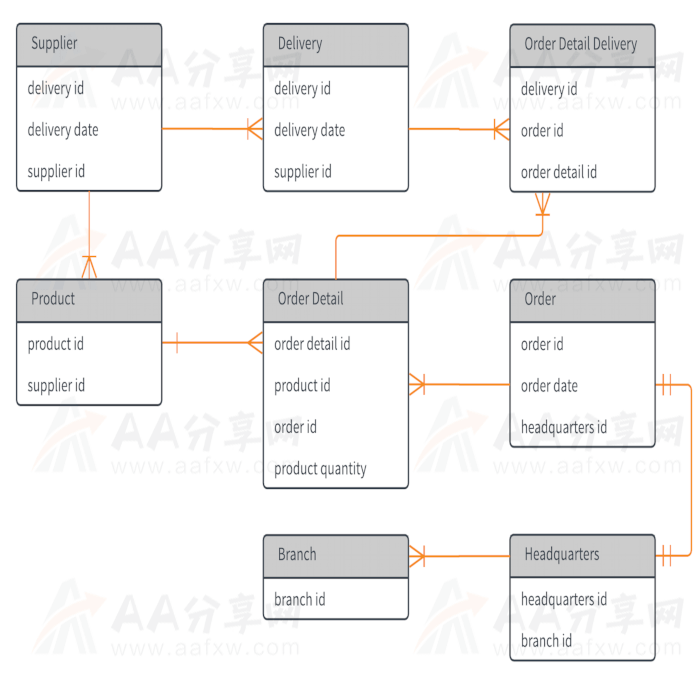
在关系型数据库里面,每个实体有自己的一张表(table),所有属性都是这张表的字段(field),表与表之间根据关联字段”连接”(join)在一起。所以,表的连接是关系型数据库的核心问题。
表的连接分成好几种类型。
1、内连接(inner join)
2、外连接(outer join)
3、左连接(left join)
4、右连接(right join)
5、全连接(full join)
以前,很多文章采用维恩图(两个圆的集合运算),解释不同连接的差异。
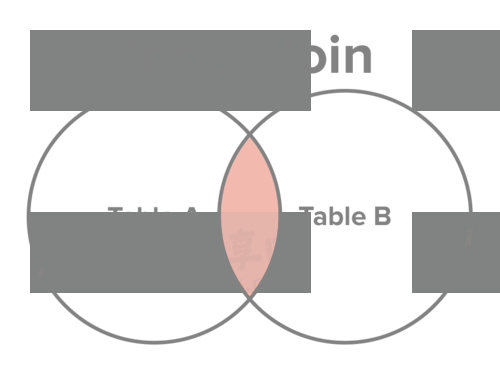
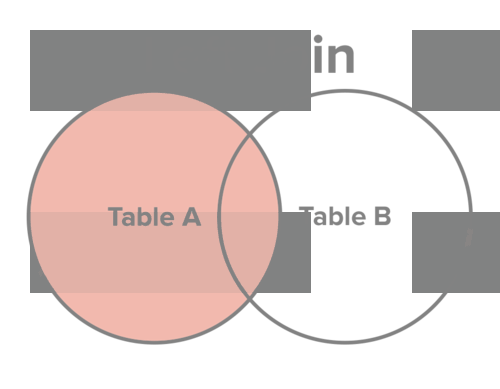


上周,我读到一篇文章,认为还有比维恩图更好的解释方式。我发现确实如此,换一个角度解释,更容易懂。
所谓”连接”,就是两张表根据关联字段,组合成一个数据集。问题是,两张表的关联字段的值往往是不一致的,如果关联字段不匹配,怎么处理?比如,表 A 包含张三和李四,表 B 包含李四和王五,匹配的只有李四这一条记录。
很容易看出,一共有四种处理方法。
1、只返回两张表匹配的记录,这叫内连接(inner join)。
2、返回匹配的记录,以及表 A 多余的记录,这叫左连接(left join)。
3、返回匹配的记录,以及表 B 多余的记录,这叫右连接(right join)。
4、返回匹配的记录,以及表 A 和表 B 各自的多余记录,这叫全连接(full join)。
下图就是四种连接的图示。我觉得,这张图比维恩图更易懂,也更准确。

上图中,表 A 的记录是 123,表 B 的记录是 ABC,颜色表示匹配关系。返回结果中,如果另一张表没有匹配的记录,则用 null 填充。
这四种连接,又可以分成两大类:内连接(inner join)表示只包含匹配的记录,外连接(outer join)表示还包含不匹配的记录。所以,左连接、右连接、全连接都属于外连接。
这四种连接的 SQL 语句如下。
SELECT * FROM A
INNER JOIN B ON A.book_id=B.book_id;
SELECT * FROM A
LEFT JOIN B ON A.book_id=B.book_id;
SELECT * FROM A
RIGHT JOIN B ON A.book_id=B.book_id;
SELECT * FROM A
FULL JOIN B ON A.book_id=B.book_id;
上面的 SQL 语句还可以加上where条件从句,对记录进行筛选,比如只返回表 A 里面不匹配表 B 的记录。
SELECT * FROM A
LEFT JOIN B
ON A.book_id=B.book_id
WHERE B.id IS null;
另一个例子,返回表 A 或表 B 所有不匹配的记录。
SELECT * FROM A
FULL JOIN B
ON A.book_id=B.book_id
WHERE A.id IS null OR B.id IS null;
此外,还存在一种特殊的连接,叫做”交叉连接”(cross join),指的是表 A 和表 B 不存在关联字段,这时表 A(共有 n 条记录)与表 B (共有 m 条记录)连接后,会产生一张包含 n x m 条记录的新表(见下图)。



